Most conversations about AI coding failures focus on the output. The generated code had a bug. The model hallucinated an API that doesn’t exist. The implementation missed an edge case. These are real problems. They are also symptoms.
The deeper failure, the one that determines whether AI-assisted development produces reliable results or expensive rework, almost always happens earlier. It happens in the research and context preparation stage, or more precisely, in the absence of one.
Error amplification is the mechanism
Think about the AI-assisted development workflow as a pipeline: Research, then Plan, then Implement. Each stage consumes the output of the previous one. And each stage amplifies the errors it inherits.
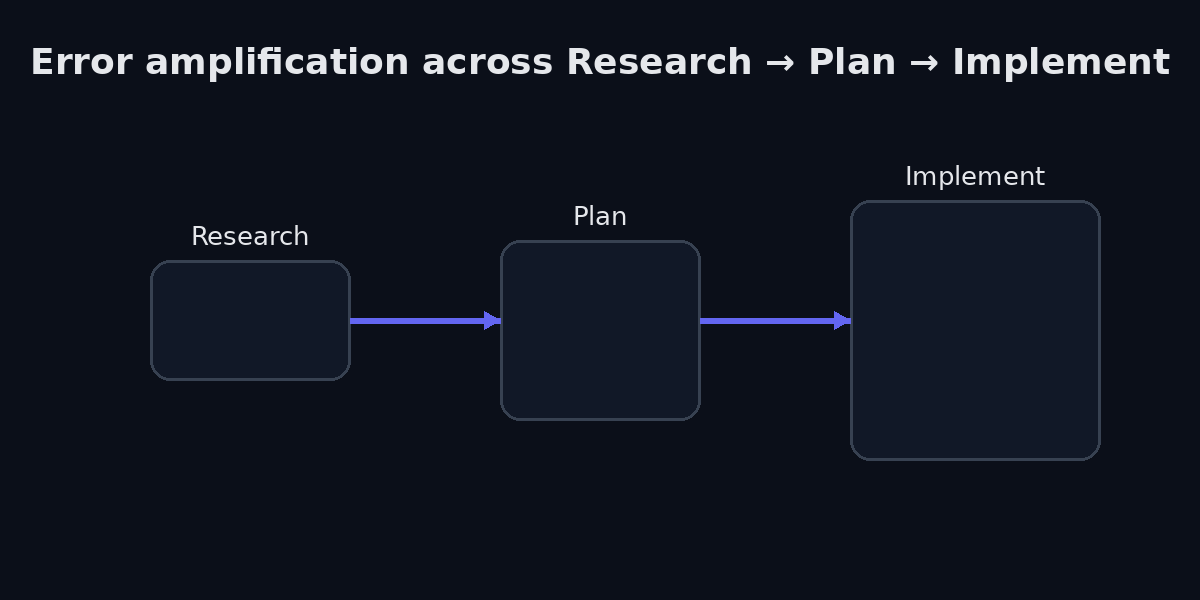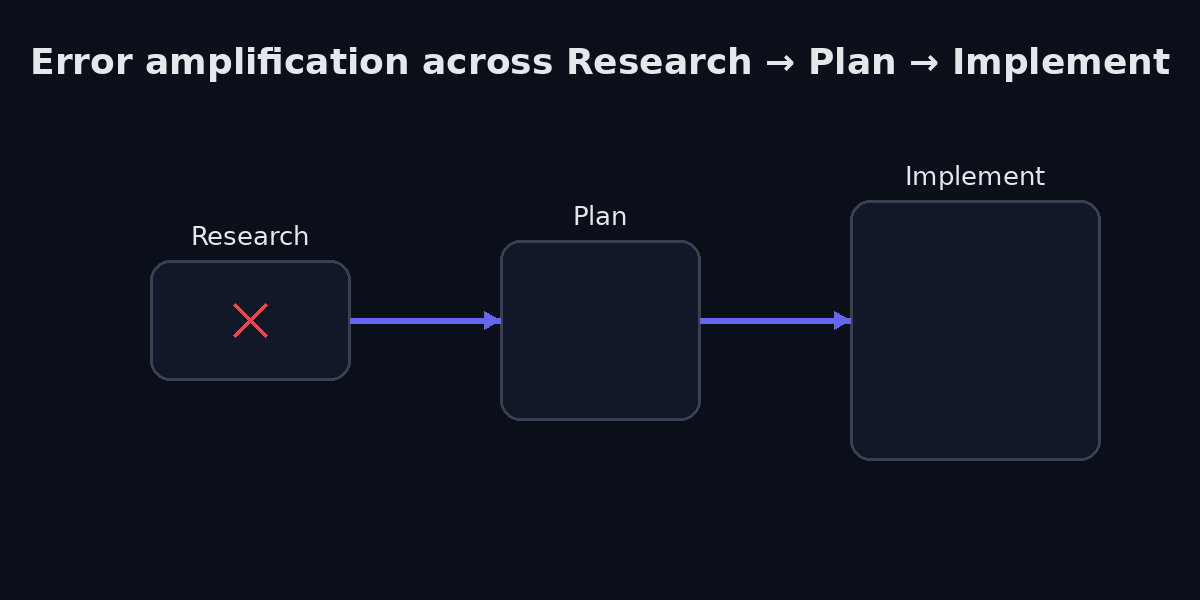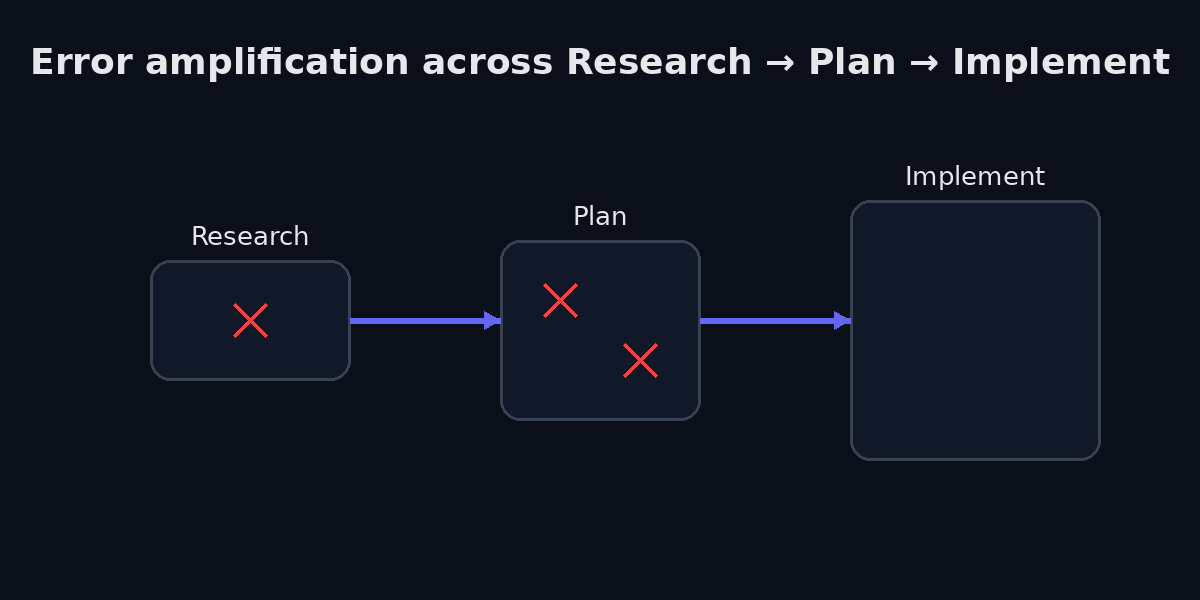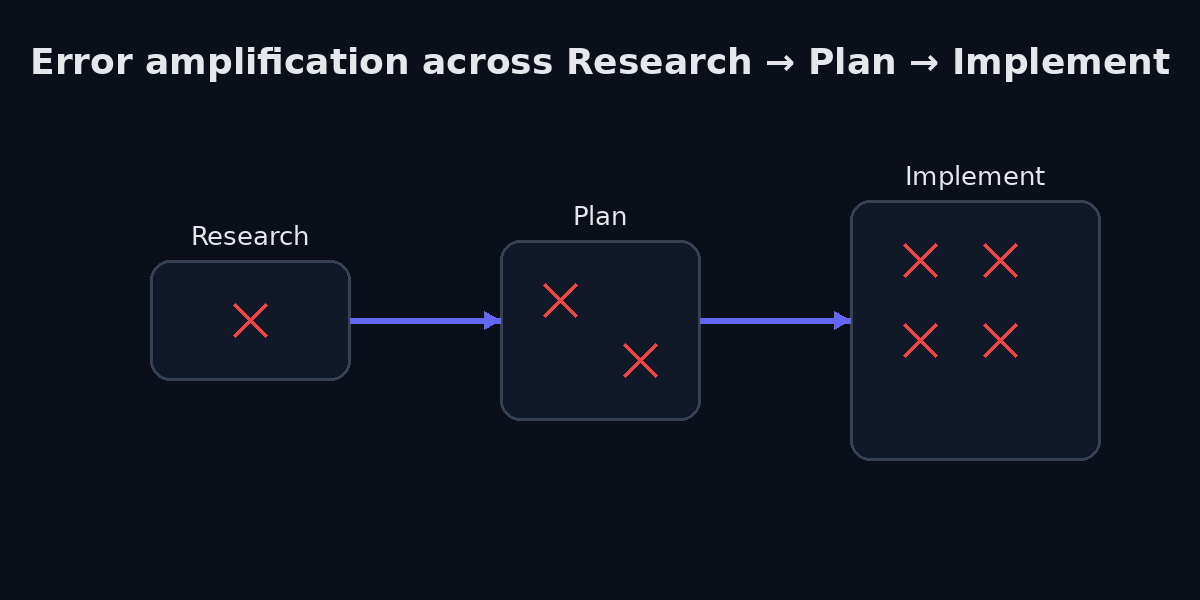
If the research stage is thin, if the developer jumps straight to prompting without understanding the existing codebase’s conventions, the API constraints, the implicit business rules, the plan inherits those gaps. The implementation then builds confidently on top of a flawed plan, producing code that is internally consistent but externally wrong.
This is not a new idea in software engineering. Brooks wrote about it in 1975. The cost of fixing a requirements error found in production is orders of magnitude higher than fixing it during design. What AI has done is compress the timeline so dramatically that teams skip the research phase entirely, because the implementation phase feels so cheap.
That cheapness is an illusion. The METR randomised controlled trial found experienced developers were 19% slower with AI on familiar codebases, and a significant contributor was the prompt-review-correct loop that AI introduces. When context is missing, that loop doesn’t run once. It runs repeatedly, each iteration attempting to patch the consequences of the original gap.

What “research” actually means in an AI workflow
In a traditional development workflow, research is implicit. A senior developer working in a codebase they know carries the context in their head: the naming conventions, the architectural patterns, the business rules that never made it into documentation. They don’t think of it as research. It’s just knowing the territory.
AI doesn’t know the territory. And this is where the failure mode lives. The developer’s implicit knowledge doesn’t transfer to the model through a prompt. What transfers is whatever the developer explicitly provides, plus whatever the model can infer from the code it can see.
The gap between what the developer knows and what the model receives is the research gap. The wider it is, the worse the output.

Concretely, research in an AI-assisted workflow means:
Codebase context: What patterns does this project use? What are the conventions for error handling, logging, testing? What does the dependency graph look like around the area you’re changing? AI tools reason over whatever context they’re given. Providing a single file when the change touches three services produces predictably poor results.
Constraint discovery: What are the non-obvious constraints? Rate limits, backward compatibility requirements, performance budgets, compliance rules? These rarely appear in the code itself. They live in wikis, Slack threads, incident postmortems, and the heads of senior engineers. If they don’t make it into the AI’s context window, they don’t exist for the purposes of generation.
Prior art review: Has this problem been solved before in the codebase? Is there an existing utility, pattern, or service that should be reused rather than duplicated? GitClear’s finding that duplicate code blocks grew at 4x the rate of prior years is, in part, a research failure: AI generating new code because it wasn’t given visibility into what already existed.
Why teams skip it
The economics of AI-assisted development create a perverse incentive to skip research. When implementation feels nearly free, when you can generate a working prototype in minutes, the upfront cost of research feels disproportionate. Why spend 30 minutes understanding the codebase when the AI can produce something in 30 seconds?
The answer is in the data. The DX Research finding that AI productivity has plateaued at 10% despite near-universal adoption is substantially a research problem. Developers are generating code faster and then spending the saved time on review, debugging, and rework, the downstream consequences of insufficient upfront context.
DORA’s finding that delivery stability drops 7.2% for every 25% increase in AI adoption tells the same story from a different angle. The instability is not coming from AI being bad at writing code. It’s coming from AI writing code without enough context to write the right code.
The Faros AI data on review times is the clearest signal: high-AI teams merged 98% more PRs but review time increased 91%. Reviewers are catching the problems that insufficient research introduced. The review stage is doing the work that the research stage should have done.

The spec-driven connection
This is why spec-driven development has gained traction so quickly. At its core, SDD is a formalised research and context preparation discipline. The specification isn’t just instructions for the AI. It’s evidence that the developer has done the upfront work of understanding what needs to be built and why.
GitHub Spec Kit’s Specify, Plan, Tasks, Implement workflow puts research first by design. The specification stage forces the developer to articulate constraints, conventions, and context before any code is generated. The 72,000 GitHub stars suggest this resonates.
But you don’t need a framework to do this. The principle is simpler than the tooling: the quality of AI-generated code is bounded by the quality of the context it receives. Invest in the input. The output follows.
The practical takeaway
Before your next AI-assisted implementation, ask three questions:
Does the AI have enough codebase context to match existing patterns, or is it guessing? If you’re providing a single file and expecting system-level consistency, the output will disappoint.
Have you surfaced the constraints that don’t live in the code? Business rules, performance requirements, compatibility guarantees. If they’re not in the prompt or the context window, they’re not in the output.
Does the AI know what already exists? Duplication is the default when the model can’t see prior art. The 30 seconds you spend pointing it at existing utilities saves the 30 minutes you’d spend in review finding the duplication.
The research stage is where AI-assisted development is won or lost. Not in the model. Not in the prompt. In the preparation that happens before either one is invoked.
Sources: METR Randomised Controlled Trial (2025). DX Research (Feb 2026). Google DORA 2024/2025. GitClear AI Copilot Code Quality Research. Faros AI (2026). Fred Brooks, The Mythical Man-Month (1975). GitHub Spec Kit.
The research gap argument is well-constructed. I want to take it seriously, because the failure mode it identifies is real. But follow the logic all the way through, and it leads somewhere uncomfortable for the AI productivity story.
The fine print on AI productivity
The original pitch for AI coding tools was simple: generate a working prototype in minutes. Type a prompt, get code, ship faster. That pitch sold a lot of subscriptions.
The research gap reframes this. Now the pitch is: spend 30 minutes gathering codebase context, document your constraints, review prior art, write a detailed specification, and then prompt the AI. The output will be better. True. But now do the time accounting.
Thirty minutes of research. A few minutes of generation. Fifteen minutes of review (because the Faros data shows review time nearly doubled for high-AI teams). Total elapsed time for an AI-assisted task: roughly 45-50 minutes. Total elapsed time for a senior developer who already knows the codebase doing it manually: roughly the same. Maybe less.
The METR finding, experienced developers going 19% slower with AI, starts to make more sense through this lens. It’s partly a research gap finding. The overhead of preparing context and reviewing output exceeds the time saved on generation.
This is what senior engineers already do
Here’s the part that bothers me about the research gap framing. The canonical post describes a discipline: understand the codebase, surface constraints, check for prior art, then implement. It presents this as a new requirement created by AI tooling.
It’s not new. It’s what competent senior engineers have always done. The naming conventions, architectural patterns, and business rules that “don’t transfer to the model through a prompt”? Those are the things a senior developer carries in their head precisely because they’ve done the research over months and years of working in the codebase.
The research gap isn’t a gap between what the developer knows and what the AI receives. It’s a gap between the senior developer’s accumulated context and the model’s blank slate. You can partially close it with specifications and documentation. But the claim that this closes the gap enough to make AI a net productivity gain for experienced developers is not supported by the data we have.
The spec-driven workaround has a cost
Spec-driven development is presented as the solution: write a specification, prepare the context, front-load the research. GitHub Spec Kit gets 72,000 stars. The methodology clearly resonates.
But consider the total workflow: Research (30 min), Write Spec (20 min), Review AI Plan (10 min), Generate (5 min), Review Output (15 min), Fix Issues (15 min). That’s 95 minutes of developer time to produce what might have taken 60-90 minutes without AI.
Where’s the gain? It’s in consistency, maybe. Junior developers following a spec-driven process might produce more reliable output than they would freestyling. But the canonical post itself notes that the biggest AI wins are for junior developers and onboarding. The research gap is hardest to close for exactly the cases where AI was supposed to help most: complex work on mature codebases.
The review stage is doing the real work
The Faros AI data is the most telling number in the entire series. High-AI teams merged 98% more PRs but review time increased 91%. The canonical post frames this as “the review stage is doing the work that the research stage should have done.”
I’d frame it differently. The review stage is where the actual engineering happens. The AI generates plausible code. The human reviewer catches the problems, applies the context the AI didn’t have, and fixes the output. The AI isn’t doing the engineering. It’s producing a first draft that a human has to substantially review and correct.
That’s a useful tool. I’m not arguing it’s worthless. But it’s a drafting assistant, not a productivity multiplier. And when you add the research overhead that this post correctly identifies as necessary, the productivity math gets very thin.
The research gap doesn’t close. It just gets counted.
The optimistic read of this post is: teams that invest in research will see better AI outcomes. The pessimistic read, and I think the more honest one, is: when you actually account for all the work required to use AI effectively, the productivity gains that surveys report largely evaporate.
AI looks productive when the research is outsourced to the developer and not counted. When you count it, you get the METR result: experienced developers, 19% slower.
Sources: METR Randomised Controlled Trial (2025). DX Research (Feb 2026). Google DORA 2024/2025. GitClear AI Copilot Code Quality Research. Faros AI (2026). Fred Brooks, The Mythical Man-Month (1975). GitHub Spec Kit.
The research gap is real. I want to be clear about that upfront, because what I’m about to argue isn’t that the problem doesn’t exist. It’s that the problem is temporary, and solving it is exactly what the next generation of AI tooling is doing.
The gap is a product roadmap
Think about the pipeline from the canonical post: Research, Plan, Implement. Right now, AI tooling has automated the Implement stage and left Research almost entirely manual. That’s an obvious gap. It’s also an obvious product opportunity.
Repo-aware agents that automatically index codebase conventions are in active development. Anthropic’s Claude Code already reads your project structure. GitHub Copilot Workspace builds context from issues and existing code. Cursor indexes entire repositories. These aren’t hypothetical. They’re shipping.
Constraint-discovery tools that read wikis, Slack threads, and incident postmortems? Also in development. Linear’s AI features already pull context from linked documents. Notion AI can summarise project constraints from scattered pages. The pattern here is clear: every gap identified in the research stage maps to a feature that someone is building right now.
Error amplification collapses when context is automated
The error amplification problem, where thin research leads to bad plans leads to wrong implementation, is real but contingent. It depends on a specific condition: the developer manually preparing context. When that manual step is automated, the amplification chain breaks.
Consider what happens when an AI coding tool can automatically identify the naming conventions in your codebase, the architectural patterns in your dependency graph, the existing utilities that overlap with what you’re about to build. The research stage doesn’t disappear. It gets executed by the tool instead of the developer.
This isn’t speculation. Early versions of this exist. Cursor’s codebase indexing already reduces the duplication problem that GitClear identified. Claude Code’s project context already surfaces conventions without the developer manually listing them. The quality is uneven, yes. But the trajectory is obvious.
The METR finding is a transitional artefact
The METR trial found experienced developers were 19% slower with AI. The canonical post correctly identifies the prompt-review-correct loop as a significant contributor. But look at what that loop actually is: it’s the developer doing research after generation instead of before it.
The developer prompts. The output is wrong because context was missing. The developer reviews, identifies the gap, corrects the prompt, regenerates. Each loop iteration is a research step disguised as a debugging step. It’s inefficient because the research is reactive rather than proactive.
Automated context preparation eliminates most of those loops. When the tool already knows the codebase patterns, the constraint set, and the prior art, the first generation is closer to correct. The review loop shrinks from five iterations to one or two. The 19% slowdown converts to a net gain.
The awkward middle period
We are in the awkward middle period of AI-assisted development. The generation capability has outrun the context capability. Developers have to do the research themselves, manually, and that overhead partially or fully offsets the generation speed.
That’s a transitional problem, not a permanent one. The research gap that the canonical post identifies is accurate as a snapshot of March 2026. It will not be accurate as a snapshot of March 2027.
The spec-driven approach is correct for right now. Write specifications. Prepare context. Do the research before you prompt. But understand that this is a manual workaround for a tooling limitation. The tooling is catching up. When it does, the developers who understand why context matters will adapt faster than those who just learned a manual process.
The research gap doesn’t need to be closed by developers. It needs to be closed by better tools. That’s already happening.
Sources: METR Randomised Controlled Trial (2025). DX Research (Feb 2026). Google DORA 2024/2025. GitClear AI Copilot Code Quality Research. Faros AI (2026). Fred Brooks, The Mythical Man-Month (1975). GitHub Spec Kit.